What is Chunking?
Chunking breaks documents into smaller sections when they are indexed. This process not only enhances the performance of retrieval engines but also allows for more efficient searches within concise text. Additionally, it overcomes token size restrictions in language models. Given that these models have a set token limit for each input, dividing the text ensures it stays within this constraint.How to Configure Chunking?
Create an Index and select theChunking options:
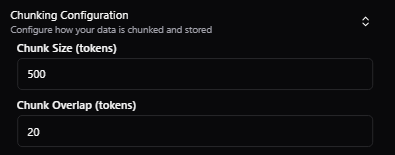
- Chunk Size: The maximum number of tokens per chunk.
- Overlap Size: The number of tokens that overlap between chunks. This is useful for ensuring that the context of the chunk is preserved. We suggest beginning with an overlap that’s roughly 10% of the chunk size.